Challenges of Moving to Serverless
Updated at February 2020
We had the opportunity to migrate data importers to a Serverless environment. The data importers were from an open environmental data provider. It is called opensense.network and is a platform that is made to simplify the access to open environmental data, by processing data from different openly available sources. The processed data is then made available over an open API. One of the data sources that are consumed is the German weather service (DWD). It provides an open accessible FTP server that contains environmental data in CSV files in a complex structure.
The WHY behind the migration
We wanted to see which parts of this application would suit in to a Serverless environment and which would not. Because of the application being divided into an API and into data importer modules, we decided to migrate exactly one module into a Serverless environment. Afterwards, we analysed our results to see benefits and trade-offs of using a Serverless environment for the data processor.
Where to Put the State?
The legacy data processor module was a monolith that was strongly object-oriented. Additionally, the implementation would create mappings between external ID’s of sensors, which measure environmental data, into internal ID’s. This mappings were saved in an local JSON file and would be used from there in the whole import process. The problem with this approach is that the Serverless environment that we chose was stateless. Therefore, one import process did not have the knowledge about already imported data sets which was persisted in the JSON file. So we decided to move this mechanism to an MongoDB that can easily be accessed by Serverless functions. It also allows multiple functions to share state. However, it comes with trade-offs of bottle-necking the well scale-able system by the MongoDB. Here it would make more sense to search for ways to move the application to an stateless variant, however this was not an option at the moment of this migration process. In the end we are satisfied with the performance of our MongoDB solution.
Control then Scale!
At the beginning we decided to have Serverless functions in that scale with the data to import. However, the application would scale so much that we completely lost the reliability factor. This happens because of external components not being able to handle the amount of incoming requests and connections. We forgot that the applications scalability is just as high as of its weakest part. Additionally, we used Apache OpenWhisk which has a limitation of how many actions can be invoked concurrently. We did not have this in mind while migrating at the beginning, but later on we realized that this is an important consideration which should be made. So we decided to actively bottleneck action activation's to scale them as much as needed but not more.
We tried to visualize both ways of scaling in the following overview. While the left side shows our naive scaling approach, the right side shows a more advanced approach.
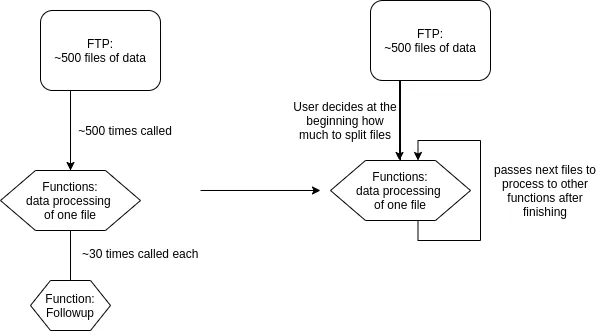
While the left more naive approach spawns an unpredictable amount of functions, because it is spawning functions based on the amount of data, the right one only spawns as many functions as the user needs and as a trade-off take some more time, but allows to predict how high the load on external systems like the API can be.
Not Every Software Design Fits Well in Serverless
The initial application was designed as the traditional monolith as the one in the first company you worked at. This is completely acceptable and is fine for most use cases, but when we tried to migrate this application into Serverless, we realized that this would be even harder because of the initial design. It used object orientation mechanisms and threading which would make it hard to migrate it with similar or better performance. We still tried to reuse the existing application in an Serverless environment and just achieved 1,3 percent of the initial import performance (we messed up hard :D). This was unacceptable and probably based on the before mentioned threading and our initial state handling. In the long run we refactored the software and the architecture so far that we would call this migration more a rewrite than a refactoring.
Take Some Time to Plan for the Migration
As we had a lot of problems in the migration process, be it performance or engineering problems, we came to the conclusion that this problems would have been foreseeable, if we had spent more time in planning the migration and the handling of states in Serverless.
Conclusion
We learned a lot about the migration of traditional monoliths into Serverless just by trying out. It was a lot of fun to explore this newer technology and to test out if we can outperform the original implementation. We think we did a satisfactory migration. Our final rewritten implementation is 10% faster than the original one and the external components being the bottlenecks in scaling. We think that such data processing tasks are a good example for the usage of Serverless, because the higher scale-ability will provide faster processing based on the amount of data. The scale-ability is even further extended if external components scale well too.